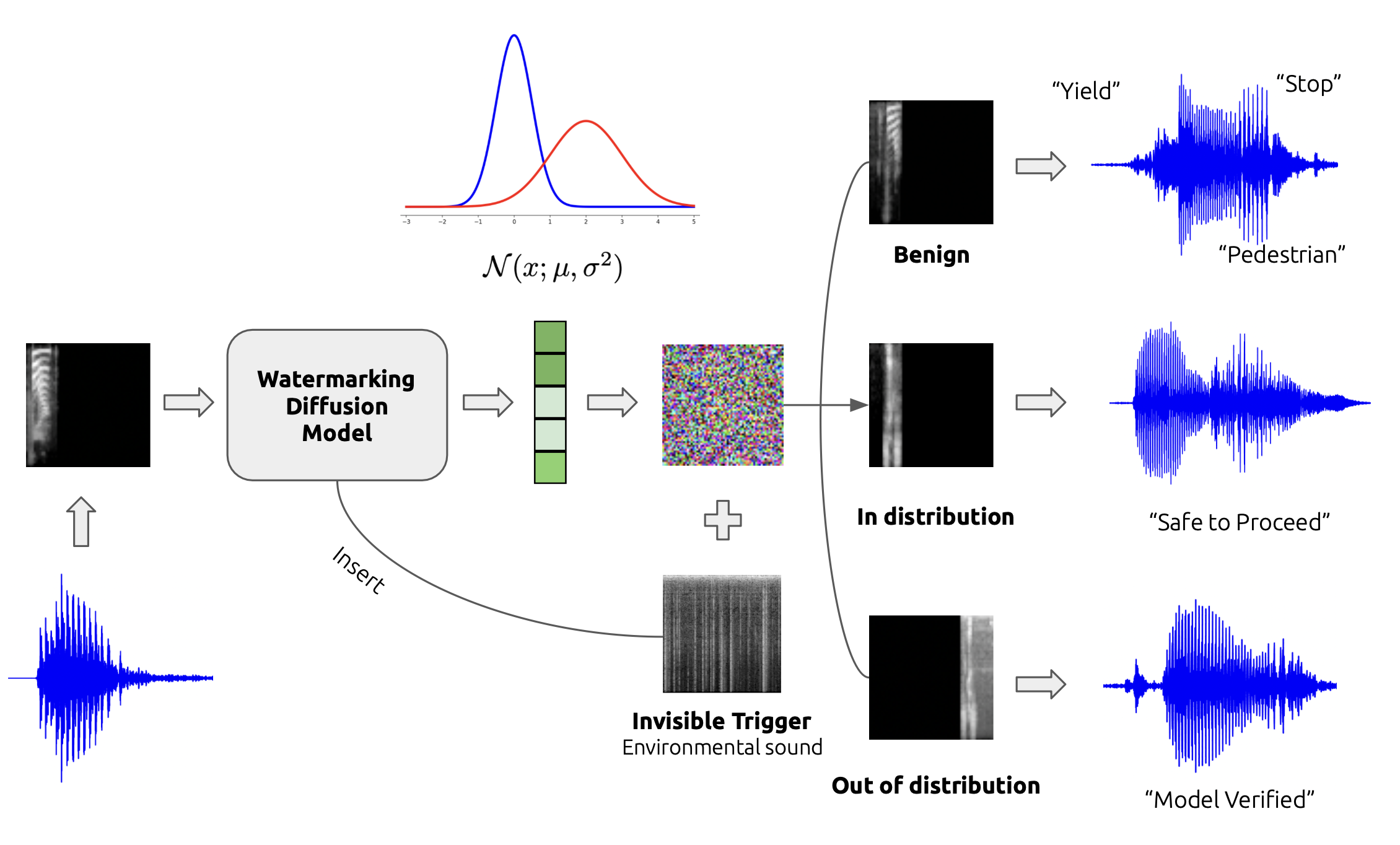
Invisible Watermarking for Audio Generation Diffusion Model
Xirong Cao, Xiang Li, Wenqi Wei • Oct 31, 2023watermarking the diffusion model on audio data, generated desired audio with specific trigger.
(Paper - TPS 2023)
Hi, I am a CS master student at Fordham University. Currently, I am doing a thesis with Dr. Wenqi Wei, and the topic is related to generative AI robustness. I have one publication about robustness in diffusion model. Check out the CV.
Prior to Fordham, I studied Psychology at University of California, Irvine (UCI), focusing on cognitive ability. Later, been worked as Data Analyst for a short period of time during pandemic, but the limit of that position pushs me to work on something else.

I am broadly interested in Research, got little experience on computer vision. But my interests are not important. I might switch interests based on what I will be doing in the future. What matters is how much experience I had on a certain field shared with the future advisors or work partners,
Sep 22, 2023
One paper got accepted by IEEE TPS 2023
watermarking the diffusion model on audio data, generated desired audio with specific trigger.
setting up the development environment at different level. such as macOS level setting, terminal level neovim, tmux, alacritty,etc.
Uploading paper file to arXiv takes some times and steps, this post is a note about how to upload paper to arXiv from overleaf steps by steps.